TrueFoundry
TrueFoundry provides an enterprise-ready AI Gateway to provide governance and observability to agentic frameworks like LangChain. TrueFoundry AI Gateway serves as a unified interface for LLM access, providing:
- Unified API Access: Connect to 250+ LLMs (OpenAI, Claude, Gemini, Groq, Mistral) through one API
- Low Latency: Sub-3ms internal latency with intelligent routing and load balancing
- Enterprise Security: SOC 2, HIPAA, GDPR compliance with RBAC and audit logging
- Quota and cost management: Token-based quotas, rate limiting, and comprehensive usage tracking
- Observability: Full request/response logging, metrics, and traces with customizable retention
Prerequisites
Before integrating LangChain with TrueFoundry, ensure you have:
- TrueFoundry Account: A TrueFoundry account with at least one model provider configured. Follow quick start guide here
- Personal Access Token: Generate a token by following the TrueFoundry token generation guide
Quickstart
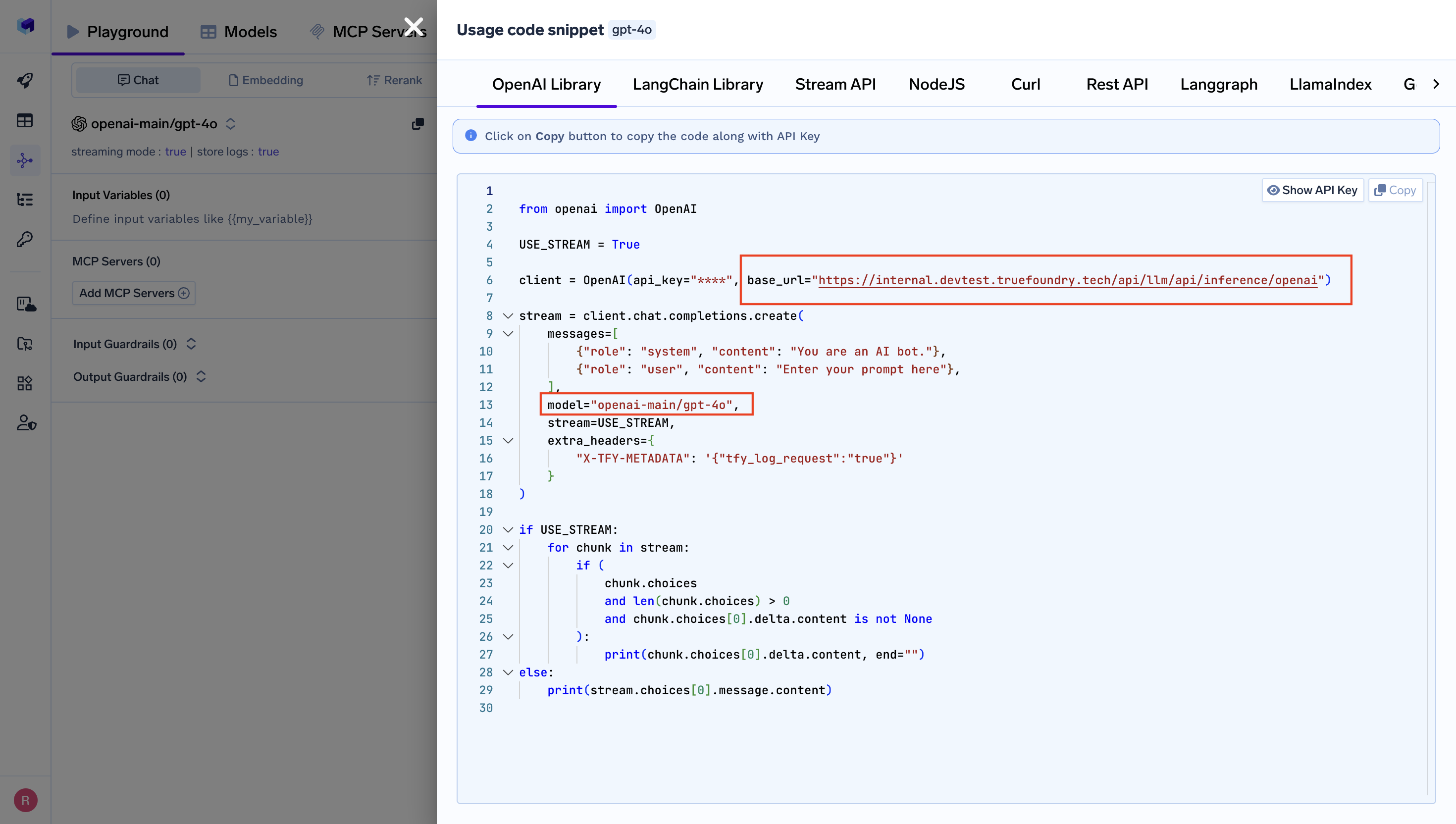
You can connect to TrueFoundry's unified LLM gateway through the ChatOpenAI interface.
- Set the
base_urlto your TrueFoundry endpoint (explained below) - Set the
api_keyto your TrueFoundry PAT (Personal Access Token) - Use the same
model-nameas shown in the unified code snippet
Installation
pip install langchain-openai
Basic Setup
Connect to TrueFoundry by updating the ChatOpenAI model in LangChain:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
api_key=TRUEFOUNDRY_API_KEY,
base_url=TRUEFOUNDRY_GATEWAY_BASE_URL,
model="openai-main/gpt-4o" # Similarly you can call any model from any model provider
)
llm.invoke("What is the meaning of life, universe and everything?")
The request is routed through your TrueFoundry gateway to the specified model provider. TrueFoundry automatically handles rate limiting, load balancing, and observability.
LangGraph Integration
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, MessagesState
from langchain_core.messages import HumanMessage
# Define your LangGraph workflow
def call_model(state: MessagesState):
model = ChatOpenAI(
api_key=TRUEFOUNDRY_API_KEY,
base_url=TRUEFOUNDRY_GATEWAY_BASE_URL,
# Copy the exact model name from gateway
model="openai-main/gpt-4o"
)
response = model.invoke(state["messages"])
return {"messages": [response]}
# Build workflow
workflow = StateGraph(MessagesState)
workflow.add_node("agent", call_model)
workflow.set_entry_point("agent")
workflow.set_finish_point("agent")
app = workflow.compile()
# Run agent through TrueFoundry
result = app.invoke({"messages": [HumanMessage(content="Hello!")]})
API Reference:HumanMessage | StateGraph
Observability and Governance
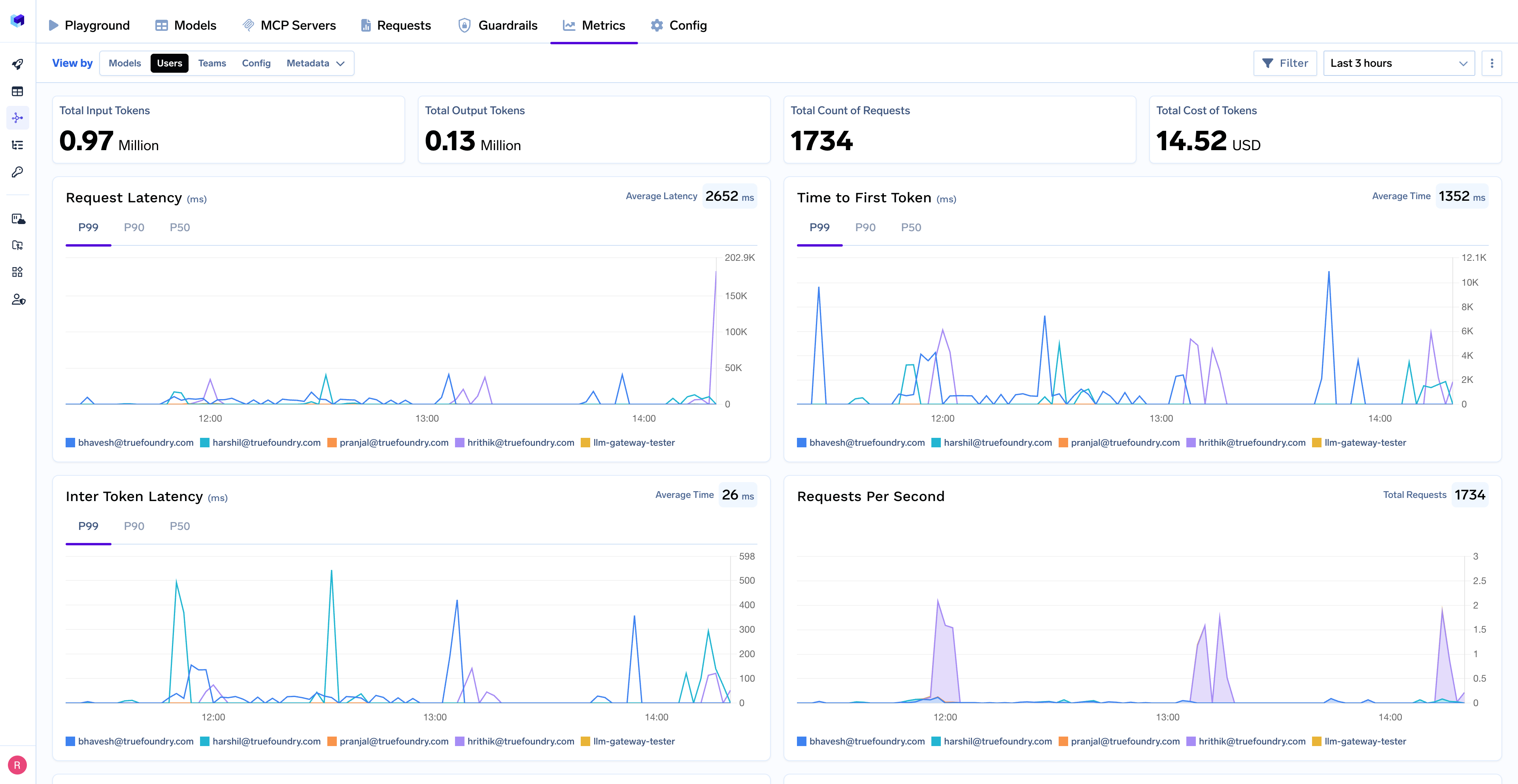
With the Metrics Dashboard, you can monitor and analyze:
- Performance Metrics: Track key latency metrics like Request Latency, Time to First Token (TTFS), and Inter-Token Latency (ITL) with P99, P90, and P50 percentiles
- Cost and Token Usage: Gain visibility into your application's costs with detailed breakdowns of input/output tokens and the associated expenses for each model
- Usage Patterns: Understand how your application is being used with detailed analytics on user activity, model distribution, and team-based usage
- Rate Limiting & Load Balancing: Configure limits, distribute traffic across models, and set up fallbacks
Support
For questions, issues, or support:
- Email: support@truefoundry.com
- Documentation: https://docs.truefoundry.com/